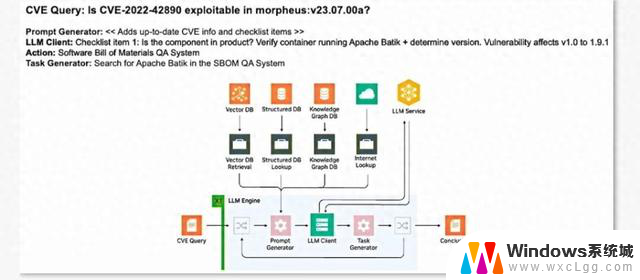
NVIDIA 实现通义千问 Qwen3 的生产级应用集成和部署指南

阿里巴巴近期开源了混合推理大语言模型(LLM)通义千问 Qwen3,此次 Qwen3 开源模型系列包含两款混合专家模型 (MoE) 235B-A22B(总参数 2,350 亿,激活参数 220 亿)和 30B-A3B,以及六款稠密(Dense)模型 0.6B、1.7B、4B、8B、14B、32B。
现在,开发者能够基于 NVIDIA GPU,使用 NVIDIA TensorRT-LLM、Ollama、SGLang、vLLM 等推理框架高效集成和部署 Qwen3 模型,从而实现极快的词元 (token) 生成,以及生产级别的应用研发。
本文提供使用 Qwen3 系列模型的最佳实践,我们会展示如何使用上述框架来部署模型实现高效推理。开发者可以根据他们的应用场景需求来选择合适的框架,例如高吞吐量、低延迟、或是 GPU 内存占用(GPU footprint)。
Qwen3 模型Qwen3 是中国首个混合推理模型,在 AIME、LiveCodeBench、ArenaHard、BFCL 等权威评测集上均获得出色的表现(信息来源于阿里巴巴官方微信公众号)。Qwen3 提供的系列开源稠密和 MoE 模型在推理、指令遵循、Agent 能力、多语言支持等方面均大幅增强,是全球领先的开源模型。
大语言模型的推理性能对于实时、经济高效的生产级部署至关重要LLM 生态系统快速演进,新模型和新技术不断更新迭代,需要一种高性能且灵活的解决方案来优化模型。
推理系统设计颇具挑战,要求也不断提升,这些挑战包括 LLM 推理计算中预填充(prefill)和解码(decode)两个阶段对于计算能力和显存大小 / 带宽的需求差异,超大尺寸模型并行分布式推理,海量并发请求,输入输出长度高度动态请求等。
目前在推理引擎上有许多优化技术可用,包括高性能 kernel、低精度量化、Batch 调度、采样优化、KV 缓存(KV cache)优化等等,选择最适合自己应用场景的技术组合需要耗费开发者大量精力。
NVIDIA TensorRT-LLM 提供了最新的极致优化的计算 kernel、高性能 Attention 实现、多机多卡通信分布式支持、丰富的并行和量化策略等,从而在 NVIDIA GPU 上实现高效的 LLM 推理。此外,TensorRT-LLM 采用 PyTorch 的新架构还提供了直观、简洁且高效的模型推理配置 LLM API,从而能够兼顾极佳性能和灵活友好的工作流。
通过使用 TensorRT-LLM,开发者可以迅速上手先进的优化技术,其中包括定制的 Attention kernel、连续批处理 (in-flight batching) 、分页 KV 缓存 (Paged KV cache)、量化(FP8、FP4、INT4 AWQ、INT8 SmoothQuant)、投机采样等诸多技术。
使用 TensorRT-LLM 运行 Qwen3 的推理部署优化下面以使用 Qwen3-4B 模型配置 PyTorch backend 为例,描述如何快捷进行基准测试以及服务化的工作。采用类似的步骤,也可以实现 Qwen3 其他 Dense 和 MoE 模型的推理部署优化。
python3 /path/to/TensorRT-LLM/benchmarks/cpp/prepare_dataset.py \
--tokenizer=/path/to/Qwen3-4B \
--stdout token-norm-dist --num-requests=32768 \
--input-mean=1024 --output-mean=1024 \
--input-stdev=0 --output-stdev=0 > /path/to/dataset.txt
cat >/path/to/extra-llm-api-config.yml <<EOF
pytorch_backend_config:
use_cuda_graph: true
cuda_graph_padding_enabled: true
cuda_graph_batch_sizes:
- 1
- 2
- 4
- 8
- 16
- 32
- 64
- 128
- 256
- 384
print_iter_log: true
enable_overlap_scheduler: true
EOF
trtllm-bench \
--model Qwen/Qwen3-4B \
--model_path /path/to/Qwen3-4B \
throughput \
--backend pytorch \
--max_batch_size 128 \
--max_num_tokens 16384 \
--dataset /path/to/dataset.txt \
--kv_cache_free_gpu_mem_fraction 0.9 \
--extra_llm_api_options /path/to/extra-llm-api-config.yml \
--concurrency 128 \
--num_requests 32768 \
--streaming
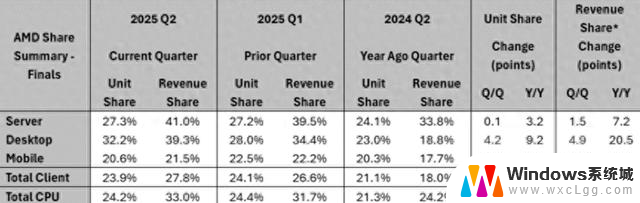
相同 GPU 环境配置下,基于 ISL = 1K, OSL = 1K,相较 BF16 基准,Qwen3-4B 稠密模型使用 TensorRT-LLM 在 BF16 的推理吞吐(每秒生成的 token 数)加速比最高可达 16.04 倍。
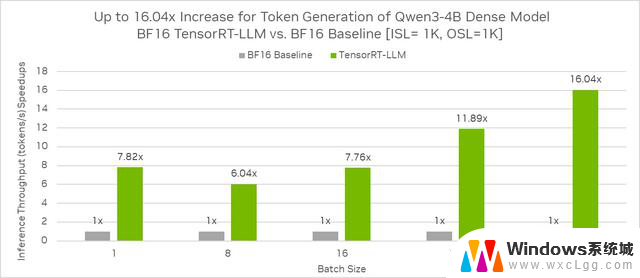
Qwen3-4B 稠密模型在 TensorRT-LLM BF16 与 BF16 基准的推理吞吐性能比较
trtllm-serve \
/path/to/Qwen3-4B \
--host localhost \
--port 8000 \
--backend pytorch \
--max_batch_size 128 \
--max_num_tokens 16384 \
--kv_cache_free_gpu_memory_fraction 0.95 \
--extra_llm_api_options /path/to/extra-llm-api-config.yml
curl -X POST "http://localhost:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "Qwen/Qwen3-4B",
"Max_tokens": 1024,
"Temperature": 0,
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
]
}'
使用 Ollama 在本地运行 Qwen3-4B:
从以下网址下载和安装最新版本的 Ollama: ollama.com/download。使用 ollama run 命令运行模型,此操作将加载并初始化模型用于后续与用户交互。ollama run qwen3:4b
"Write a python lambda function to add two numbers" - Thinking mode enabled
"Write a python lambda function to add two numbers /no_think" - Non-thinking mode
使用 SGLang 运行 Qwen3-4B:
安装 SGLang 库pip install "sglang[all]"
huggingface-cli download --resume-download Qwen/Qwen3-4B --local-dir ./
python -m sglang.launch_server \
--model-path /ssd4TB/huggingface/hub/models/ \
--trust-remote-code \
--device "cuda:0" \
--port 30000 \
--host 0.0.0.0
curl -X POST "http://localhost:30000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "Qwen/Qwen3-4B",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
]
}'
使用 vLLM 运行 Qwen3-4B
安装 vLLM 库pip install vllm
vllm serve "Qwen/Qwen3-4B" \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.85 \
--device "cuda:0" \
--max-num-batched-tokens 8192 \
--max-num-seqs 256
curl -X POST "http://localhost:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "Qwen/Qwen3-4B",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
]
}'
总结仅仅通过几行代码,开发者即可通过包括 TensorRT-LLM 在内的流行推理框架来使用最新的 Qwen 系列模型。
此外,对模型推理和部署框架的技术选型需要考虑到诸多关键因素,尤其是在把 AI 模型部署到生产环境中时,对性能、资源和成本的平衡。